After completing this lesson, you’ll be able to:
Implementing a self-serve system makes use of the appropriate services available on FME Server: data download or data upload.
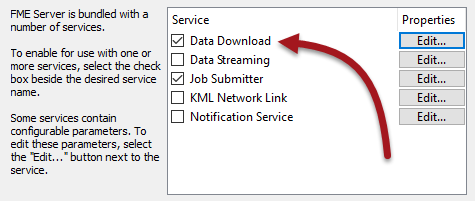
Creating and using a data download service is very easy. A workspace becomes available for data download use when the author registers it against the Data Download service when publishing it to FME Server:
Once registered this way, Data Download becomes an acceptable way to run this workspace. This might be run in a number of ways, one of which is selecting Data Download as the service in the FME Server Web interface:

The results of the workspace are not written to a specific output location; instead, they are delivered to the user in the form of a hyperlink to a zipped dataset:
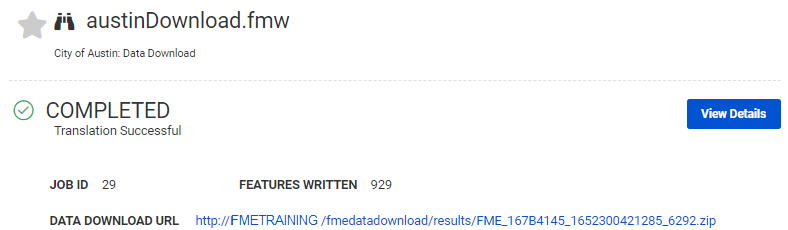
The ZIP file will contain any data written to a file- or format-based format writer (i.e. not to a database or web URL). It can include the output from one or more writers and can contain one or more output files.
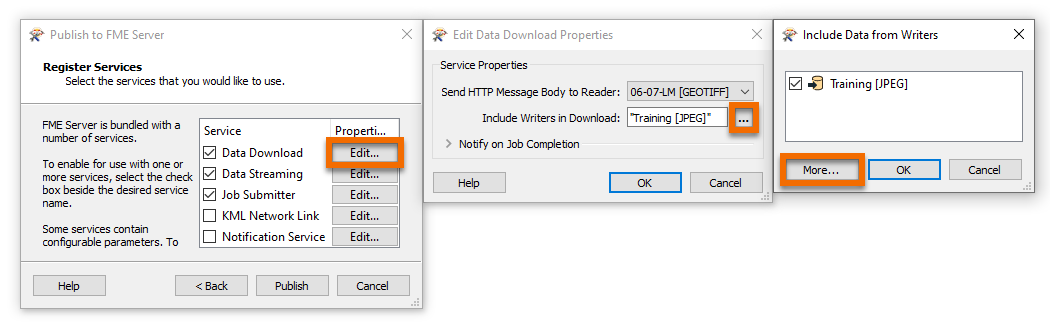
To control the folder structure of the ZIP file, from the Register Services page, click Edit beside the Data Download service. Next, then click the '...' button beside Include Writers in Download, then click on 'More...'. This will open a dialog that will let you set up the paths for each of the files within the zip file.
The Data Upload service is different in that a workspace is not registered specifically to this utility service. Instead, publishing source dataset parameters in the workspace allows data upload to take place.
On FME Server there are two ways to upload data, depending on the requirements for the data. There is a specific Data Upload Service and there is also the Resources file system.
The Data Upload Service uploads data to a particular workspace in a particular repository. The data is held temporarily for the workspace to be run.
The Resources file system allows data to be uploaded to a folder for use by any workspace in any repository. This upload is persistent and the data is held there for as long as required.
When creating a customized solution that involves data upload, the author can choose whether to use the Data Upload service or the Resources file system instead. The main difference is whether the data needs to reside on the Server permanently (Resources) or just temporarily (Data Upload).
Although most people look at self-serve mostly in the context of Data Download, that is not the only self-serve service available.
Data Streaming is another service that a workspace can be registered against:
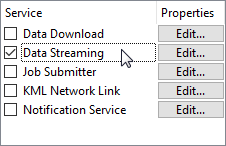
Whereas the Job Submitter service writes data, and the Data Download service returns a link to the data, a Data Streaming service returns a file or the data itself, streamed back to the client.
For example, if the Data Streaming URL for a workspace is posted into a web browser, the data will be automatically downloaded and opened in whatever application the browser associates with that file type (some data might open directly in the web browser itself).
Alternatively, the URL can be used directly as the source for a client application, like a GIS tool. When the client actively downloads the contents on a regular basis – as a GeoRSS reader would – then you have a feed, which is significantly different from a regular data download service.
What Formats Can Be Streamed?
You can use any workspace with the data streaming service, provided it writes data in a format that is file-based or folder-based (similar to the Data Download service).
If an output dataset is comprised of more than one file, the data streaming service automatically creates a compressed (zip) folder out of the data. For example, AutoCAD DWG format could be streamed, whereas Esri Shape would be returned in a zipped file.
The most popular formats to stream are those that have a suitable client to read the feed. Some of the main formats that are output using the data streaming services include:
MIME Types in Workspaces
A MIME header is a component of a file or e-mail message that is capable of indicating the content type of the file; for example, Content-Type: text/plain indicates a simple text file.
The application chosen to open a streamed file will depend on the MIME type and file association on the client’s system.
Setting MIME type is most important for FME writers where the content is not specifically defined by the writer. For example, the HTML writer has no MIME type setting because it is obviously providing text/HTML. The TextFile writer has a MIME type setting because the nature of its contents is ambiguous; it might be writing plain text (text/plain) or XML (text/XML) or it might even write the contents of a blob attribute containing a raster png image (image/png):
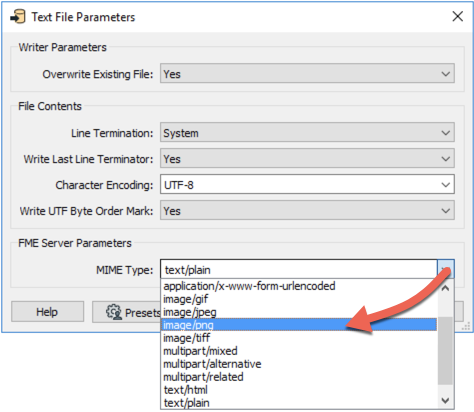
Here the author is saying that the content of the text file is valid PNG and should be opened in the default PNG application (possibly a web browser or graphic editor).
The Job Submitter service simply accepts and runs workspace job requests. The Job Submitter service works with any workspace. The data is read and written as specified in the workspace, but not directly provided to the user running the workspace.
Google describes a KML Network Link as a type of bookmark; a link from Google Earth (or any other KML-reading application) to the true set of data.
In FME you can register any workspace that writes KML as a KML Network Link service:
Running the workspace using this service merely returns a small KMZ (compressed KML) file that contains this "bookmark". The bookmark is a link back to the workspace using a URL that points to the Data Streaming service.
When Google Earth opens a KML Network Link service from FME Server, it receives the link to the workspace:
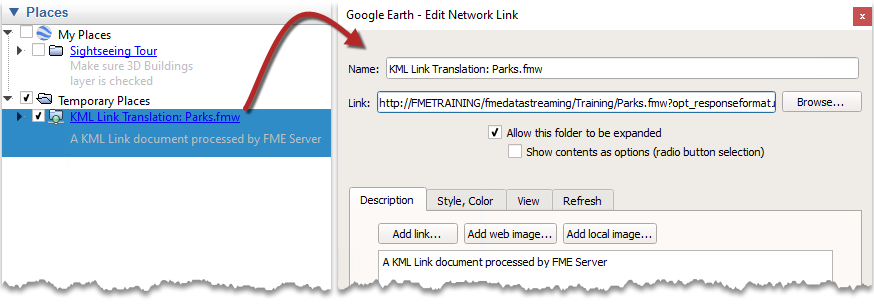
When the link is followed, it triggers FME Server into running the workspace and returning the results as a stream of KML data.
Because Google Earth permits a refresh rate for network links, the translation can be re-run at a user-defined interval. This way the results are always as up-to-date as the chosen interval.
Of course, in this scenario the output is never written to a permanent dataset; the resulting data is simply streamed to Google Earth, which writes it to a cache.
The FME Server Notification Service pushes data to and from FME Server in the form of messages when an event occurs. It uses a system of publications and subscriptions. This system has largely been replaced by Automations. In most cases, it is easier to use an Automation writer in your workspace rather than publishing to the Notification Service.
